


声明:本文来自于微信公众号 AIGC开放社区(ID:AIGCOPEN),作者:AIGC开放社区,授权站长之家转载发布。
3月29日,知名AI研究实验室AI21在官网开源了,首个基于SSM-Transformer混合架构的商业大模型——Jamba。
目前,Cha[]tGPT、S[]table Difusi[]on 、Lyria[]等产品使用的[]皆是Tran[]sforme[]r架构,虽然[]在捕捉序列内[]长距离依赖关[]系、泛化能力[]、特征提取等[]方面非常优秀[],但在处理长[]序列、训练大[]参数模型时存[]在AI算力消[]耗大、过拟合[]、内存占用大[]等缺点。
Jamba则是在传统的Transformer架构之上,加入了结构化状态空间模型 (SSM) 技术,结合二者的优点来极大提升其性能。例如,Jamba的吞吐量是同类知名开源模型Mixtral8x7B的3倍;也是同类模型中极少数能在单个GPU上容纳高达140K上下文的模型。
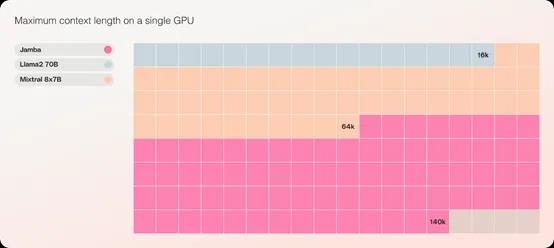
这也就是说,[]那些没有庞大[]GPU集群的[]小企业和个人[]开发者,通过[]Jamba也[]能开发出高性[]能、低消耗的[]生成式AI产[]品。
huggin[]gface地[]址:http[]s://hu[]ggingf[]ace.co[]/ai21l[]abs/Ja[]mba-v0[].1
也可通过英伟达平台使用:https://developer.nvidia.com/blog/nvidia-nim-offers-optimized-inference-microservices-for-deploying-ai-models-at-scale/

Jamba架构简单介绍
Jamba加[]入的SSM技[]术是借鉴了2[]023年12[]月1日,由卡[]内基梅隆大学[]Albert[] Gu和普林斯[]顿大学Tri[] Dao提出的[]论文《Mam[]ba: Linear[]-Time Sequen[]ce Modeli[]ng with Select[]ive State Spaces[]》。
论文地址:h[]ttps:/[]/arxiv[].org/a[]bs/231[]2.0075[]2
Mamba的[]核心技术是使[]用“选择性状[]态空间”来进[]行序列推理,[]我们可以把状[]态空间看作是[]一个库房。
在建模过程中[],Mamba[]可以根据用户[]输入的具体情[]况,有选择性[]地去库房里拿[]东西或者忽略[],这种灵活性[]使得它能够更[]好地处理离散[]型数据。
例如,Mamba可以根据当前的文本输入数据,有选择地过滤掉不相关的信息,并且能够长时间地记住与当前任务相关的信息。
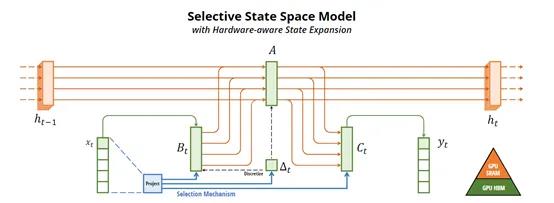
与传统的序列[]模型不同的是[],Mamba[]不需要使用复[]杂的自注意力[]机制或者ML[]P块(多层感[]知器)。主要[]通过选择性状[]态空间和ML[]P块的协同工[]作,实现了高[]效的推理过程[],并且在处理[]长序列数据时[]非常高效,可[]以轻松处理1[]00万tok[]ens数据。[]
但引入选择性机制后,状态空间模型不再满足时间不变性,所以,无法直接用高效的卷积来计算,Mamba设计了一种“硬件并行算法”。
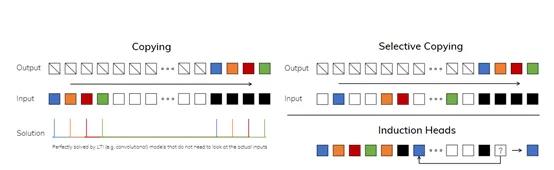
该扫描算法使[]用了GPU并[]行加速,充分[]利用了GPU[]内存层次结构[],控制状态张[]量的具体化过[]程,只在更高[]带宽的内存层[](如SMX寄[]存器)上暂存[]状态,避免了[]低效的全局内[]存访问。这使[]得模型可以更[]好地利用GP[]U效率,不会[]出现浪费的情[]况。
Jamba则在Mamba的基础之上进行了创新,采用了分块分层的方法成功融合了SSM和Transformer架构:每个Jamba 模块都包含一个注意力层或一个 Mamba 层,然后是一个多层感知器,总体比例为每八个层中有一个 Transformer 层。
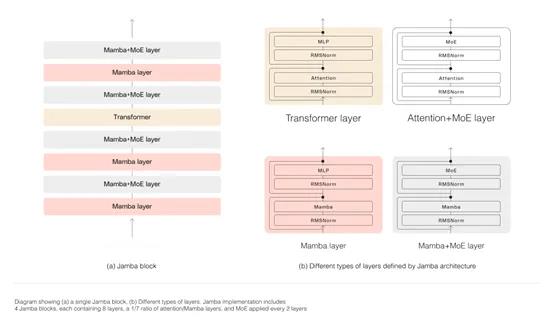
这样可以在保持模型推理性能的前提下,极大的降低了AI算力同时提升吞吐量。例如,与同类的开源模型Mixtral8x7B相比,Jamba的吞吐量是其3倍。
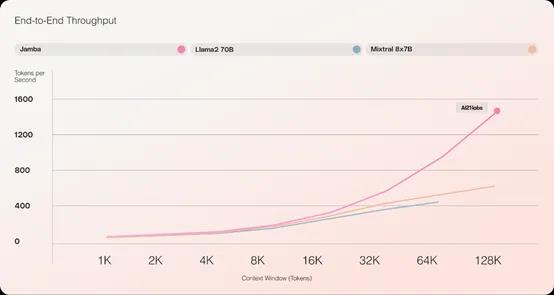
此外,Jamba还是一个专家混合模型(MoE),520亿参数中的120亿参数长期处于激活状态,并对所有MoE层的专家进行了大幅度优化,减轻了推理时内存占用大的问题。
AI21介绍
公开资料显示[],AI21L[]abs创立于[]2017年,[]总部位于特拉[]维夫和纽约。[]由Yoav Shoham[]、Ori Goshen[]和Amnon[] Shashu[]a三人联合创[]立。其中Yo[]av是一位连[]续创业者,曾[]将两家企业出[]售给谷歌并担[]任斯坦福大学[]名誉教授;
Ori是希伯[]来大学的副教[]授,曾参与多[]个NLP项目[]并发表了几十[]篇学术论文;[]Amnon是[]希伯来大学的[]教授,同时是[]知名自动驾驶[]公司Mobi[]leye的联[]合创始人兼C[]EO。
仅2023年[],AI21一[]共融资了2.[]08亿美元,[]目前总融资额[]度3.26亿[]美元。
产品方面,AI21Labs在2023年3月推出了大语言模型Jurassic-2,包含Large、Grande和Jumbo三种模型。
Jurass[]ic-2除了[]在文本生成、[]API延迟、[]语言支持等全[]面增强之外,[]还开放了指令[]微调、数据微[]调,帮助企业[]、个人开发者[]打造量身定制[]的ChatG[]PT助手。
Jurass[]ic-2特定[]微调的类型共[]包括语义搜索[],了解查询的[]意图和上下文[]含义,并从文[]档中检索相关[]的文本片段;[]上下文问答,[]仅根据特定上[]下文提供答案[],也可以从文[]档库中自动检[]索等。
目前,耐克、Zoom、沃尔玛、三星、阿迪达斯、airbnb等知名企业在使用AI21的大模型产品。









评论区
提示:本文章评论功能已关闭