


声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权站长之家转载发布。
【新智元导读】OpenAI被曝出了新项目「草莓」,据悉能提前计划,自主浏览网页,还能进行深度研究。草莓由大量通用数据上后训练而成,推理能力显著提高。根据OpenAI最近的AGI路线图,草莓疑似已达Level2。
昨天刚刚被曝[]出AGI五级[]路线图,今天[]OpenAI[]的新项目St[]rawber[]ry也被曝出[]了。
不过,大家其[]实对它都很熟[]悉——就是曾[]经的Q*。
听闻消息的马斯克,也补上这么一句评论——「以前的说法是,AI末日是回形针灾难,没想到是永远的草莓田。」
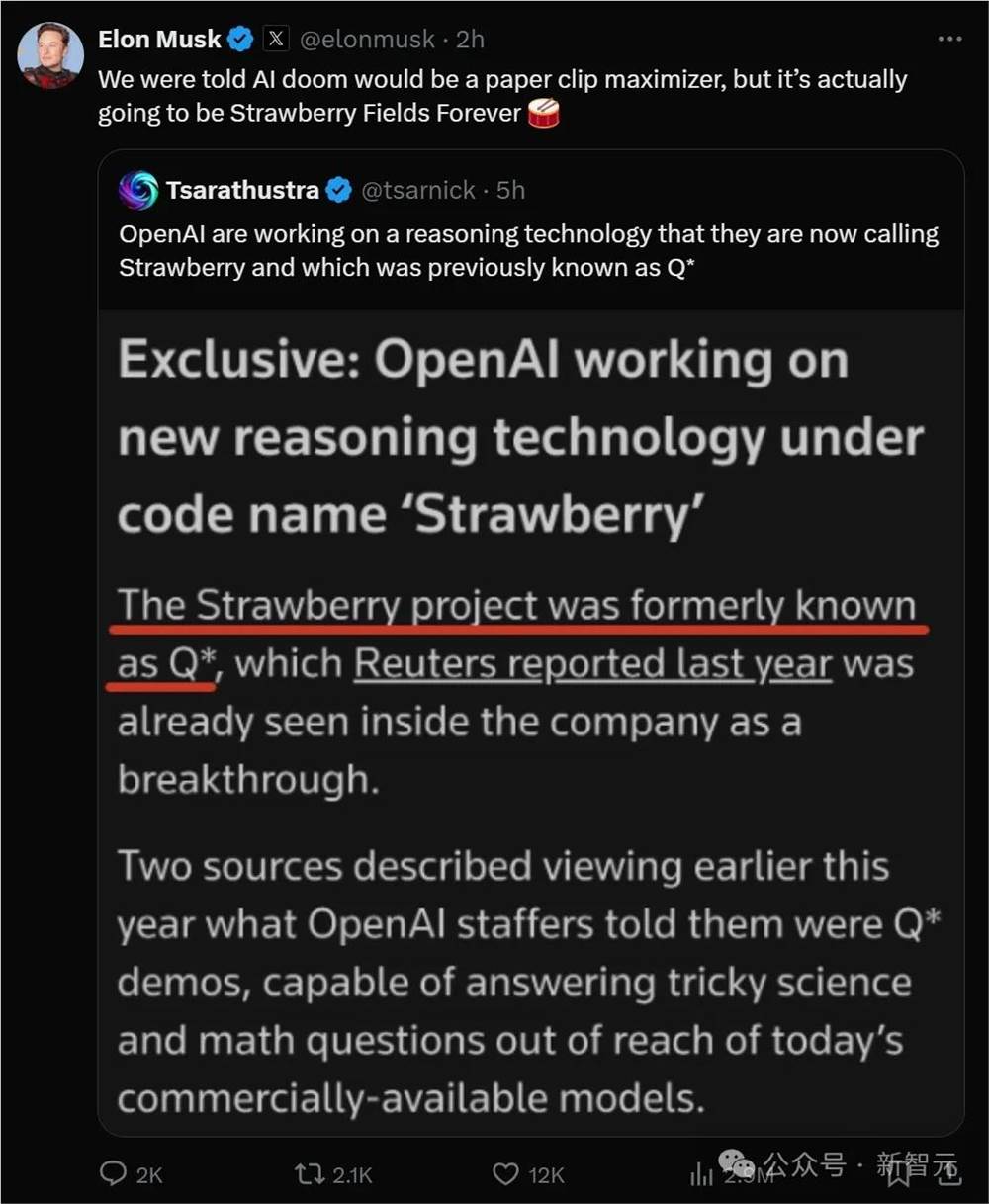
根据路透社在[]5月份看到的[]内部文件,O[]penAI团[]队正在全力研[]究Straw[]berry项[]目。
Strawb[]erry具体[]是如何运作,[]即使在Ope[]nAI内部也[]是高度保密的[]。
因此,何时公开发布,时间也是未知。

从AGI五级[]路线图来看,[]具有推理能力[]还能自主可靠[]浏览网页的S[]trawbe[]rry,可能[]已经到了L2[]的级别
而就在本周,[]OpenAI[]刚在内部会议[]上展示了某个[]demo,据[]称推理能力接[]近人类水平。[]
结合路线图的[]曝光,一切都[]太巧了。
对此,网友们[]纷纷猜测,O[]penAI一[]定还在憋个大[]的。
显著提高AI[]模型的推理能[]力
文件显示,S[]trawbe[]rry模型的[]目的,是为了[]使公司的AI[]不仅能生成查[]询答案,还能[]提前计划,足[]够自主且可靠[]地浏览互联网[],进行Ope[]nAI所称的[]「深度研究」[]。
而这个目标,[]根据对十多位[]AI研究人员[]的采访,目前[]尚未有任何A[]I模型实现。[]
路透社表示,Strawberry就是去年的Q*,后者在OpenAI内部已经实现突破。

当被问询到Strawberry的更多细节时,OpenAI发言人表示——
我们希望我们的AI模型能像我们一样看待和理解世界。对新AI能力的持续研究是行业中的常见做法,大家普遍相信,这些系统的推理能力会随着时间的推移而改善。
知情人士表示,OpenAI希望Strawberry的创新能显著提高其AI模型的推理能力,并补充说,Strawberry涉及了一种AI模型在经过非常大的数据集预训练后的一种特殊处理方式。
而路透社采访[]的研究人员表[]示,推理是A[]I达到人类或[]超人类智能的[]关键。
虽然LLM可[]以飞速总结密[]集文本、撰写[]优美文章,但[]在解决对人类[]很直观的常识[]性问题时,如[]识别逻辑谬误[]和玩井字棋时[],表现并不佳[],常常出现幻[]觉。
研究者表示,[]在AI背景下[]的推理,就需[]要一个模型让[]AI能提前计[]划,反映物理[]世界的运作,[]并且可靠地解[]决复杂的多步[]骤问题。
改进AI模型[]的推理能力,[]被认为是解锁[]这些模型潜力[]的关键。有了[]推理能力,模[]型在进行重大[]科学发现、规[]划构建新的软[]件应用上,都[]会有可观的提[]升。
Sam Altman[]此前也曾表示[],今后AI领[]域最重要的进[]展,将「围绕[]推理能力展开[]」。
而其他巨头,[]如谷歌、Me[]ta、微软等[],都在尝试不[]同技术,来改[]进AI模型的[]推理能力。
沿着目前的路[]线,有可能实[]现让LLM将[]想法和长期规[]划纳入其预测[]方式吗?图灵[]三巨头之一的[]LeCun对[]此持唱衰态度[]。
他坚决认为,LLM不具备类人的推理能力。
后训练,能让LLM学会推理吗
要克服这些挑[]战,对Ope[]nAI来说S[]trawbe[]rry就是关[]键。最近几个[]月,Open[]AI曾私下向[]开发者和外部[]人士暗示过,[]即将发布具有[]显著先进推理[]能力的技术。[]
据悉,Str[]awberr[]y包括一种被[]称为「后训练[]」的特殊方法[],即在Ope[]nAI的生成[]式AI模型已[]经在大量通用[]数据上「训练[]」后,调整基[]础模型以特定[]方式优化其性[]能。
模型开发的后[]训练阶段涉及[]「微调」等方[]法,这一过程[]几乎如今所有[]的LLM都在[]用,比如RL[]HF。
知情人士表示,Strawberry类似于斯坦福大学在2022年开发的一种方法——「自我教导推理者」(Self-Taught Reasoner,简称STaR)。

论文地址:h[]ttps:/[]/arxiv[].org/a[]bs/220[]3.1446[]5
论文作者之一[],斯坦福教授[]Noah Goodma[]n表示,ST[]aR使AI模[]型能够通过迭[]代创建自己的[]训练数据,来[]「自我提升」[]到更高的智能[]水平。
理论上,可以让语言模型实现超越人类水平的智能。
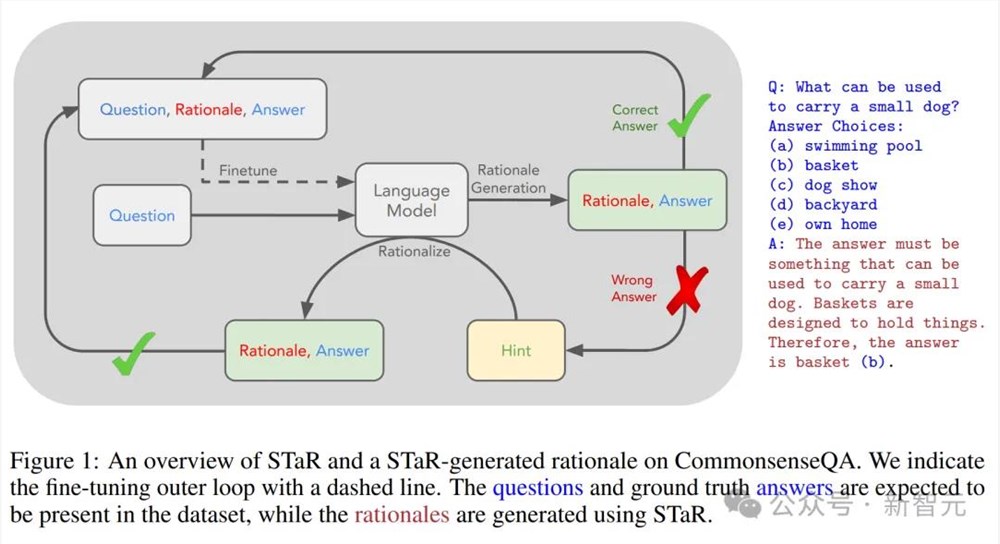
结果显示,在算术、数学文字题和常识推理中,STaR能够有效地将少量的少样本提示转化为大量的推理数据集,从而显著提升性能。在CommonsenseQA上,STaR比少样本基线提高了35.9%,比直接预测答案的微调基线提高了12.5%,其表现与一个大30倍的微调模型相当(72.5%对73.0%)。
另一项OpenAI希望让Strawberry具备的能力之一,是执行长时间任务(LHT),这指的是需要模型提前计划,并在较长时间内执行一系列动作的复杂任务。
文件显示,为[]了实现这一目[]标,Open[]AI正在创建[]、训练和评估[]被称为「深度[]研究」数据集[]的模型。
OpenAI[]非常希望模型[]能够利用这些[]能力,通过一[]个称为「CU[]A」的计算机[]使用Agen[]t来自主浏览[]网络,并根据[]其发现采取行[]动来进行研究[]。
此外,Ope[]nAI还计划[]测试其在软件[]和机器学习工[]程师工作中的[]应用能力。
神秘项目疑似[]Strawb[]erry加持[]
就在2024[]年7月初的一[]次全员会议上[],OpenA[]I内部曾对一[]个神秘研究项[]目做了展示。[]
据称,它所展[]现出的推理能[]力,已经达到[]了类人的水平[]。
结合前文的信[]息,路透怀疑[]这可能与St[]rawber[]ry有关,但[]目前还无法确[]定。
而同一时间曝光出的这张通往AGI的路线图,似乎也印证了OpenAI即将会有新的进展。
可以看到,OpenAI将最终抵达AGI终点,划分了五大等级:
L1:聊天机器人,具有对话能力的AI。
L2:推理者[],像人类一样[]能够解决问题[]的AI。
L3:智能体[],不仅能思考[],还可以采取[]行动的AI系[]统。
L4:创新者[],能够协助发[]明创造的AI[]。
L5:组织者,可以完成组织工作的AI。
OpenAI表示,我们目前正处在第一级别,不过很快会达到第二个级别,即推理者。
所谓推理者,[]也就是指可以[]解决博士水平[]的基本问题的[]系统。
OpenAI[] CTO曾透露[],OpenA[]I接下来将致[]力于研究在特[]定任务上博士[]级别的智能,[]也许就在一年[]或一年半之后[]实现。
也就是说,我们还有18月的时间,即将看到级别二的下一代模型。

Q*重出江湖
2023年1[]1月,Ope[]nAI的神秘[]Q*项目,引[]爆整个AI社[]区。
泄露出来的信[]息,Q*的能[]力,是能够解[]决小学阶段的[]数学问题。
虽然在大多数[]人看来,这并[]不是什么令人[]印象深刻的事[],但这的确是[]朝向AGI迈[]出的一大步,[]堪称重要的技[]术里程碑。
因为Q*解决[]的,是以前从[]未见过的数学[]题。
Ilya做出[]的突破,使O[]penAI不[]再受限于获取[]足够的高质量[]数据来训练新[]模型,而这,[]正是开发下一[]代模型的主要[]障碍。
那几周内,Q*的演示一直在OpenAI内部流传,所有人都很震惊。
据悉,Ope[]nAI的一些[]人认为Q*可[]能是Open[]AI在AGI[]上取得的一个[]突破。AGI[]的定义是:「[]在最具经济价[]值的任务中,[]超越人类的自[]主系统」
所以,Q*究[]竟是啥呢?
这要从一项1[]992年的技[]术Q-lea[]rning说[]起。
简单来说,Q-learning是一种无模型的强化学习算法,旨在学习特定状态下某个动作的价值。其最终目标是找到最佳策略,即在每个状态下采取最佳动作,以最大化随时间累积的奖励。
斯坦福博士Silas Alberti由此猜测,Q*很可能是基于AlphaGo式蒙特卡罗树搜索token轨迹。下一个合乎逻辑的步骤是以更有原则的方式搜索token树。这在编码和数学等环境中尤为合理。

随着几位AI[]大佬的下场,[]大家的观点,[]愈发不谋而合[]了。
AI2研究科学家Nathan激动地写出一篇长文,猜测Q假说应该是关于思想树+过程奖励模型。并且认为Q*假说很可能和世界模型有关!


文章地址:h[]ttps:/[]/www.i[]nterco[]nnects[].ai/p/[]q-star[]
他猜测,如果Q*(Q-Star)是真的,那么它显然是RL文献中的两个核心主题的合成:Q值和A*(一种经典的图搜索算法)。
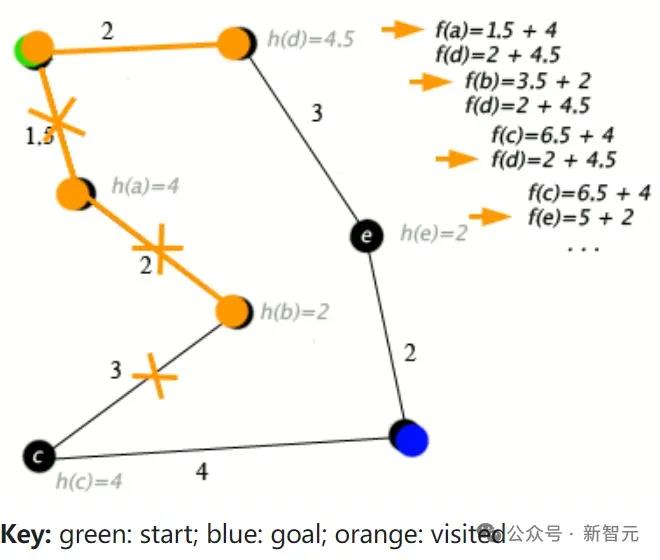
A*算法的一个例子
GPT-4o放出新演示
话说,Ope[]nAI最近似[]乎没有多大动[]静了。
最近的技术进[]步,我们可以[]从OpenA[]I开发者体验[]主管Roma[]in Huet在旧[]金山人工智能[]工程师世界博[]览会上的分享[]中感受一下。[]
这些分享主要[]是产品演示,[]包括GPT-[]4o Voice、[]ChatGP[]T桌面版、S[]ora和Vo[]ice Engine[](未发布),[]
虽然示例有所不同,但用到的模型能力,与5月份在巴黎VivaTech活动上所展示的基本一致。
在这个演示中[],主管让GP[]T-4o表演[]了多种语调,[]比如激情四射[]版、悄悄话版[]等。
GPT-4o可以即时听懂Huet的命令,立马做出正确的反应,在场观众给出欢呼。
接下来,Hu[]et向Cha[]tGPT出示[]了金门大桥的[]手绘图,让它[]猜猜自己在哪[]里。
ChatGP[]T马上猜出来[]这是哪个大桥[],并说出Hu[]et在旧金山[],还认出了他[]在纸上的手写[]字——「Bo[]njour Develo[]per」!
随后,Huet又迅速给了它一堆任务,比如认出查理芒格的书,随机翻一页后迅速总结书页大意等等,ChatGPT没有任何迟疑,迅速给出了正确答案,效率令人惊叹。
下一步,Huet把prompt发给Sora,Sora立马就生成的符合要求的视频——自然纪录片风格的丛林中的树蛙。
美丽的自然纪录片中,一个极近特写镜头拍摄了一只五彩缤纷的树蛙在雾气弥漫的浓密丛林中攀爬树枝和树叶,拍摄时间为白天。使用35mm胶片进行远摄,并带有景深效果。
随后,Hue[]t从视频中提[]取了6帧,然[]后把这6帧发[]给了GPT-[]4o Vision[],让它描述自[]己看到了什么[]。
很快,一段内容详实的故事就被创作了出来:
在雾气弥漫的浓密森林深处,一只色彩斑斓的青蛙小心翼翼地沿着覆盖苔藓的树枝前行。它明亮的绿色身体上点缀着醒目的黑黄图案,在茂密的植被中显得格外显眼。
在这条危险的[]路径上,青蛙[]保持警觉。每[]一步都很慎重[],粘性的脚趾[]牢牢抓住粗糙[]的树皮。树枝[]轻轻摇晃,显[]示出它精妙的[]平衡感。
到达树枝的边[]缘时,青蛙评[]估着前方的空[]隙。突然,它[]爆发出一股能[]量,跃了过去[]。但就在后腿[]推离时,脚滑[]了一下。短暂[]地悬在空中,[]青蛙笨拙但安[]全地落回树枝[]上。
尽管有些失误,这只坚韧的两栖动物重新站稳了脚跟,展示了野生环境中生命的顽强。它毫不气馁,准备进行下一次跳跃,坚定不移。
最后,Huet展示了voice engine的神奇功能。
他先录了一段[]自己的语音,[]然后把刚才S[]ora生成的[]树蛙视频发给[]voice engine[],下一秒,上[]面那段树蛙视[]频的长故事,[]就用他的声音[]被读了出来![]观众们掌声雷[]动。
然后,这段故[]事又被Voi[]ce Engine[]用法语、日语[]重新读了一遍[](感觉翻译的[]淘汰又近了一[]步)。
在产品层面,[]OpenAI[]已经做到了如[]此先进的地步[],如果再加上[]Strawb[]erry的推[]理能力,Op[]enAI离A[]GI的实现,[]恐怕是要很近[]了。
参考资料:
https:[]//www.[]reuter[]s.com/[]techno[]logy/a[]rtific[]ial-in[]tellig[]ence/o[]penai-[]workin[]g-new-[]reason[]ing-te[]chnolo[]gy-und[]er-cod[]e-name[]-straw[]berry-[]2024-0[]7-12/
https://www.youtube.com/watch?v=yJHw33cVeHo






评论区
提示:本文章评论功能已关闭