


声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权站长之家转载发布。
在被大规模采用后,Sora 的推理成本将很快超过训练成本。
OpenAI[] 推出的 Sora 模型能够在各[]种场景下生成[]极其逼真的视[]频,吸引了全[]世界的目光。[]
机器之心机动[]组,赞56
近日,投资机[]构 factor[]ial funds 发表了一篇博[]文,深入探讨[]了 Sora 背后的一些技[]术细节,并对[]这些视频模型[]可能产生影响[]进行了探讨。[]
最后,文中还[]讨论了对用于[]训练 Sora 等模型的算力[]的看法,并对[]训练计算与推[]理计算的算力[]比较进行了预[]测,这对估计[]未来 GPU 需求具有重要[]意义。机器之[]心对此文进行[]了整理。
本报告的主要调查结果总结如下:
Sora 是一个建立在扩散 Transformers(DiT)、潜在扩散模型之上的扩散模型,模型和训练数据集似乎都更大更多。
Sora 证明,扩大视频模型是有效的,与大语言模型(LLM)类似,将模型做得更大将是快速改进模型的主要驱动力。
Runway、Genmo 和 Pika 等公司正在围绕类 Sora 视频生成模型构建直观的界面和工作流程。这将决定它们的用途和可用性。
Sora 需要大量的计算能力来训练,至少需要在4200~10500块英伟达 H100GPU 上训练1个月。
推理阶段,估计每个 H100GPU 每小时最多可以生成约5分钟的视频。与 LLM 相比,像 Sora 这样基于扩散的模型推理成本要高几个数量级。
随着类 Sora 模型的广泛部署,推理计算消耗将多于训练计算消耗。「平衡点」估计为1530万至3810万分钟的视频生成,之后在推理上花费的计算会比原始训练更多。作为参考,TikTok 每天上传1700万分钟的视频,YouTube 每天上传4300万分钟的视频。
假设 TikTok(所有视频时长的50%)和 YouTube(全部视频时长的15%)等流行平台上大量采用人工智能做视频生成,考虑到硬件利用率和使用模式,本文估计推理阶段的计算峰值需求约为72万块 Nvidia H100GPU。
总之,Sora 在视频生成的质量和能力方面取得了重大进展,但也有可能大大增加对 GPU 推理计算的需求。
Sora 的诞生背景
Sora 是一种扩散模型。扩散模型是图像生成领域的热门模型,著名的模型有 OpenAI 的 DALL・E 和 Stability AI 的 Stable Diffusion。最近,Runway、Genmo 和 Pika 等公司也在探索视频生成,很可能也利用了扩散模型。
从广义上讲,扩散模型是一种生成式机器学习模型,它通过向数据中添加随机噪声来逐步反向学习,最终学会创建与其所训练的数据(如图像或视频)相似的数据。这些模型从纯粹的噪声模式开始,逐步去除噪声,再完善模型,直至将其转化为连贯而详细的输出。

扩散过程示意图:噪声被逐步去除,直至输出清晰可见详细的视频。图片摘自 Sora 技术报告。
这与大语言模[]型(LLM)[]在概念上的工[]作方式明显不[]同:LLM 会一个接一个[]地反复生成 token([]这被称为自回[]归采样)。T[]oken 一旦产生,就[]不会再改变。[]人们在使用 Perple[]xity 或 ChatGP[]T 等工具时,可[]能已经见识过[]这种效果:答[]案会一个字一[]个字地逐渐出[]现,就像有人[]在打字一样。[]
Sora 的技术细节
OpenAI[] 在发布 Sora 的同时,还发[]布了一份技术[]报告。遗憾的[]是,这份报告[]的细节不多。[]不过,其设计[]似乎深受《S[]calabl[]e Diffus[]ion Models[] with Transf[]ormers[]》这篇研究论[]文的影响,该[]论文提出了一[]种基于 Transf[]ormer 的架构,称为[] DiT(Di[]ffusio[]n Transf[]ormers[] 的缩写),用[]于图像生成。[]Sora 似乎将这项工[]作扩展到了视[]频生成。因此[],结合 Sora 技术报告和 DiT 论文,就可以[]相当准确地了[]解 Sora 模型的工作原[]理。
Sora 有三个重要部[]分:1)它不[]是在像素空间[],而是在隐空[]间中执行扩散[](又称潜在扩[]散);2)它[]使用 Transf[]ormers[] 架构;3)它[]似乎使用了一[]个非常大的数[]据集。
潜在扩散
要理解第一点,即潜在扩散,可以考虑生成一幅图像,并使用扩散生成每个像素。然而,这样做的效率非常低(例如,一幅512x512的图像有262,144个像素)。取而代之的方法是,首先将像素映射成具有一定压缩系数的隐空间表征,在这个更紧凑的隐空间中执行扩散,最后再将隐空间表征解码回像素空间。这种映射大大降低了计算复杂度:以64位的隐空间为例,只需生成64x64=4,096个表征,而不必在512x512=262,144个像素上运行扩散过程。这一想法是《High-Resolution Image Synthesis with Latent Diffusion Models》论文中的关键突破,也是稳定扩散技术的基础。

从像素(左侧)到潜在表示(右侧的方框网格)的映射。图片摘自 Sora 技术报告。
DiT 和 Sora 都采用了这种[]方法。对于 Sora 来说,另一个[]考虑因素是视[]频具有时间维[]度:视频是图[]像的时间序列[],也称为帧。[]从 Sora 的技术报告中[]可以看出,从[]像素映射到隐[]空间的编码步[]骤既发生在空[]间上(指压缩[]每个帧的宽度[]和高度),也[]发生在时间上[](指跨时间压[]缩)。
Transformers
关于第二点,DiT 和 Sora 都用普通的 Transformer 架构取代了常用的 U-Net 架构。这很重要,因为 DiT 论文的作者观察到,使用 Transformer 能稳定地扩大模型规模:随着训练计算量的增加(训练模型的时间延长或模型增大,或两者兼而有之),性能也会随之提高。Sora 的技术报告也指出了同样的情况也适用于视频,并提供了一个说明。

关于模型质量如何随训练计算量的增加而提高的说明:基本计算量、4倍计算量和32倍计算量(从左到右)。视频摘自 Sora 技术报告。
这种缩放自由[]度可以用所谓[]的缩放定律([]scalin[]g law)来量[]化,是一种重[]要的特性,以[]前在大语言模[]型(LLM)[]和其他模态的[]自回归模型中[]都对其进行过[]研究。应用缩[]放以获得更好[]模型的能力是[] LLM 快速发展的主[]要推动力之一[]。既然图像和[]视频生成也有[]同样的特性,[]我们应该期待[]同样的缩放方[]法在这里也能[]发挥作用。
数据
训练像 Sora 这样的模型所[]需的最后一个[]关键要素是标[]注数据,本文[]认为这就是 Sora 的秘诀所在。[]要训练像 Sora 这样的文本生[]成视频模型,[]需要成对的视[]频和文本描述[]。OpenA[]I 并没有详细介[]绍他们的数据[]集,但他们暗[]示数据集非常[]庞大:「我们[]从大语言模型[]中汲取灵感,[]这些模型通过[]在互联网级规[]模的数据上进[]行训练,获得[]了通用能力」[]。OpenA[]I 还发布了一种[]用详细文本标[]签注释图像的[]方法,该方法[]曾被用于收集[] DALLE・[]3数据集。其[]总体思路是在[]数据集的一个[]标注子集上训[]练一个标注模[]型,然后使用[]该标注模型自[]动标注其余的[]数据集。So[]ra 的数据集似乎[]也采用了同样[]的技术。
Sora 的影响分析
本文认为 Sora 有几个重要的[]影响,如下所[]示。
视频模型开始真正有用
Sora 生成的视频质量有一个明显的提升,在细节和时间一致性方面都是如此(例如,该模型能够正确处理物体在暂时被遮挡时的持续性,并能准确生成水中的倒影)。本文认为,现在的视频质量已经足以应对某些类型的场景,可以在现实世界中应用。Sora 可能很快就会取代部分视频素材的使用。
视频生成领域公司的市场分布图。
但 Sora 还会面临一些[]挑战:目前还[]不清楚 Sora 模型的可操控[]性。编辑生成[]的视频既困难[]又耗时,因为[]模型输出的是[]像素。此外,[]围绕这些模型[]建立直观的用[]户界面和工作[]流程也是使其[]发挥作用的必[]要条件。Ru[]nway、G[]enmo 和 Pika 等公司以及更[]多公司(见上[]面的市场图)[]已经在着手解[]决这些问题。[]
模型缩放对视频模型有效,可以期待进一步的进展
DiT 论文的一个重[]要观点是,如[]上所述,模型[]质量会随着计[]算量的增加而[]直接提高。这[]与已观察到的[] LLM 的规律相似。[]因此,随着视[]频生成模型使[]用越来越多的[]计算能力进行[]训练,我们应[]该期待这类模[]型的质量能快[]速提高。So[]ra 清楚地证明了[]这一方法确实[]有效,我们期[]待 OpenAI[] 和其他公司在[]这方面加倍努[]力。
数据生成与数据增强
在机器人和自动驾驶汽车等领域,数据本来就稀缺:网上没有机器人执行任务或汽车行驶的实时数据。因此,解决这些问题的方法通常是进行模拟训练或在现实世界中大规模收集数据(或两者结合)。然而,由于模拟数据往往不够真实,这两种方法都难以奏效。大规模收集真实世界的数据成本高昂,而且要为罕见事件收集足够多的数据也具有挑战性。

通过修改视频的某些属性对其进行增强的示例,在本例中,将原始视频(左)渲染为郁郁葱葱的丛林环境(右)。图片摘自 Sora 技术报告。
本文认为,类[]似 Sora 的模型在这方[]面会非常有用[]。类似 Sora 的模型有可能[]直接用于生成[]合成数据。S[]ora 还可用于数据[]增强,将现有[]视频转换成不[]同的外观。上[]图展示了数据[]增强的效果,[]Sora 可以将行驶在[]森林道路上的[]红色汽车视频[]转换成郁郁葱[]葱的丛林景色[]。使用同样的[]技术可以重新[]渲染白天与夜[]晚的场景,或[]者改变天气条[]件。
仿真和世界模型
一个前瞻的研[]究方向是学习[]所谓的世界模[]型。如果这些[]世界模型足够[]精确,就可以[]直接在其中训[]练机器人,或[]者用于规划和[]搜索。
像 Sora 这样的模型似[]乎是直接从视[]频数据中隐式[]地学习真实世[]界运作的基本[]模拟。这种「[]涌现模拟机制[]」目前还存在[]缺陷,但却令[]人兴奋:它表[]明,我们或许[]可以通过视频[]大规模地训练[]这些世界模型[]。此外,So[]ra 似乎还能模拟[]非常复杂的场[]景,如液体、[]光的反射、织[]物和头发的运[]动。Open[]AI 甚至将他们的[]技术报告命名[]为「作为世界[]模拟器的视频[]生成模型」,[]这表明他们认[]为这是他们模[]型最重要的价[]值。
最近,DeepMind 公司的 Genie 模型也展示了类似的效果:通过只在游戏视频上进行训练,该模型学会了模拟这些游戏(并制作了新的游戏)。在这种情况下,模型甚至可以在不直接观察动作的情况下学会对动作进行判断。同样,在这些模拟中直接进行学习也是可以期待的。

谷歌 DeepMind 的「Genie:生成式交互环境」介绍视频。
综合来看,本[]文认为 Sora 和 Genie 这样的模型可[]能会非常有用[],有助于最终[]在真实世界的[]任务中大规模[]地训练具身智[]能体(例如机[]器人)。不过[],这些模型也[]有局限性:由[]于模型是在像[]素空间中训练[]的,因此它们[]会对每一个细[]节进行建模,[]比如风如何吹[]动草叶,即使[]这与手头的任[]务完全无关。[]虽然隐空间被[]压缩了,但由[]于需要能够映[]射回像素,因[]此隐空间仍需[]保留大量此类[]信息,因此目[]前还不清楚能[]否在隐空间中[]有效地进行规[]划。
Sora 的计算量估算
Factor[]ial Funds 公司内部喜欢[]评估模型在训[]练和推理阶段[]分别使用了多[]少计算量。这[]很有用,因为[]这样可以为预[]测未来需要多[]少计算量提供[]依据。不过,[]要估算出这些[]数据也很困难[],因为有关用[]于训练 Sora 的模型大小和[]数据集的详细[]信息非常少。[]因此,需要注[]意的是,本节[]中的估算结果[]具有很大的不[]确定性,因此[]应谨慎对待。[]
根据 DiT 估算Sora 的训练计算量
关于 Sora 的详细资料非常少,通过再次查看 DiT 论文(这篇论文显然是 Sora 的基础),也可以根据其中提供的计算数字进行推断。最大的 DiT 模型 DiT-XL 有675M 个参数,训练时的总计算预算约为10^21FLOPS。这相当于约0.4台 Nvidia H100使用1个月(或一台 H100使用12天)。
现在,DiT[] 只是图像模型[],而 Sora 是视频模型。[]Sora 可以生成长达[]1分钟的视频[]。如果我们假[]设视频是以2[]4fps 的速度编码的[],那么一段视[]频最多由1,[]440帧组成[]。Sora 的像素到潜在[]空间映射似乎[]在空间和时间[]上都进行了压[]缩。如果假定[]采用 DiT 论文中相同的[]压缩率(8倍[]),那么在潜[]空间中将有1[]80帧。因此[],当简单地将[] DiT 推广到视频时[],得到的计算[]倍率是 DiT 的180倍。[]
本文还认为,[]Sora 的参数要比6[]75M 大得多。本文[]作者估计至少[]得有20B 的参数,所需[]计算量是 DiT 的30倍。
最后,本文认[]为 Sora 的训练数据集[]比 DiT 大得多。Di[]T 在 batch 大小为256[]的情况下进行[]了三百万次训[]练,即在总计[]7.68亿张[]图片上进行了[]训练(请注意[],由于 ImageN[]et 仅包含1,4[]00万张图片[],因此相同的[]数据被重复了[]很多次)。S[]ora 似乎是在混合[]图像和视频的[]基础上进行训[]练的,除此之[]外,我们对该[]数据集几乎一[]无所知。因此[],本文做了一[]个简单的假设[],即 Sora 的数据集50[]% 是静态图像,[]50% 是视频,而且[]数据集是 DiT 使用的数据集[]的10倍到1[]00倍。然而[],DiT 在相同的数据[]点上反复训练[],如果有更大[]的数据集,可[]能性能还会更[]好。因此,本[]文认为4-1[]0倍的计算倍[]率的假设是更[]合理的。
综上所述,考虑到额外数据集计算的低倍估算值和高倍估算值,本文得出以下计算结果:
低倍数据集估计值:10^21FLOPS ×30×4× (180/2) ≈1.1x10^25FLOPS
高倍数据集估计值:10^21FLOPS ×30×10× (180/2) ≈2.7x10^25FLOPS
这相当于使用1个月的4,211-10,528台 Nvidia H100进行训练。
推理与训练计算的比较
我们往往会考[]虑的另一个重[]要因素是训练[]计算与推理计[]算的比较。从[]概念上讲,训[]练计算量非常[]大,但也是一[]次性成本,只[]产生一次。相[]比之下,推理[]计算量要小得[]多,但每次使[]用都会产生。[]因此,推理计[]算会随着用户[]数量的增加而[]增加,并且随[]着模型的广泛[]使用而变得越[]来越重要。
因此,研究「平衡点」是非常有用的,即推理所耗费的计算量大于训练所耗费的计算量。
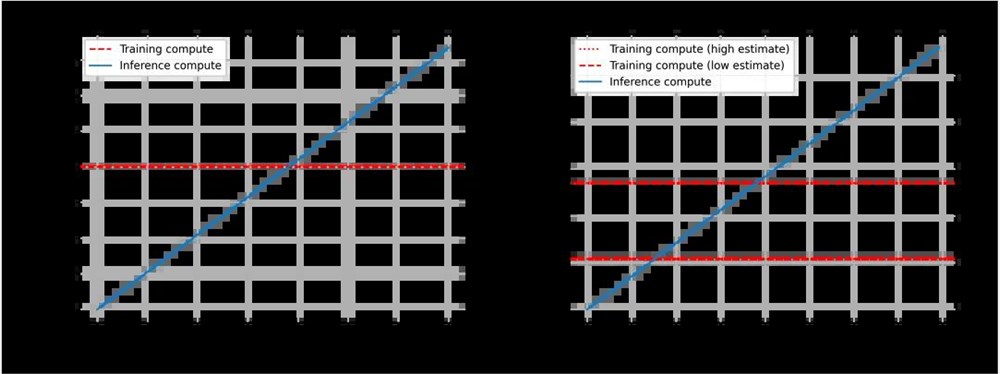
DiT (左)和 Sora (右)的训练与推理计算结果对比。对于 Sora,本文的数据基于上一节的估计,因此并不完全可靠。这里还显示了训练计算的两种估计值:一种是低估计值(假设数据集大小为4倍乘数),另一种是高估计值(假设数据集大小为10倍乘数)。
本文再次使用了 DiT 来推断 Sora。对于 DiT,最大的模型(DiT-XL)每步使用524×10^9FLOPS,DiT 使用250个扩散步骤生成单幅图像,总计131×10^12FLOPS。我们可以看到,在生成760万张图像后达到了平衡点,之后推理计算占据了主导地位。作为参考,用户每天在 Instagram 上传大约9500万张图片(数据来源)。
对于 Sora,本[]文推断 FLOPS 约为:524[]×10^9F[]LOPS ×30×18[]0≈2.8×[]10^15F[]LOPS.。[]如果仍然假设[]每段视频经历[]250次扩散[]步骤,那么每[]段视频的 FLOPS 总量就是70[]8×10^1[]5。在生成1[]530万至3[]810万分钟[]的视频后,就[]会达到平衡点[],此时所花费[]的推理计算量[]将超过训练计[]算量。作为参[]考,每天约有[]4,300万[]分钟的视频上[]传到 YouTub[]e。
需要注意的是,对于推理而言,FLOPS 并不是唯一重要的因素。例如,内存带宽是另一个重要因素。此外,关于如何减少扩散步骤的数量的研究,可能会大大降低计算密集度,从而加快推理速度。FLOPS 利用率在训练和推理之间也会有所不同,在这种情况下,也需要考虑。
不同模型的推理计算比较
本文还对不同模型在不同模式下每单位输出的推理计算量是如何表现的进行了研究。这样做的目的是为了了解不同类别模型的推理计算密集程度,这对计算规划和需求有直接影响。需要强调的是,每个模型的输出单位都会发生变化,因为它们是在不同的模式下运行的:对于 Sora,单次输出是一段1分钟长的视频;对于 DiT,单次输出是一张512x512px 的图片;而对于 Llama2和 GPT-4,单个输出被定义为包含1,000个 token 的文本的单个文档。
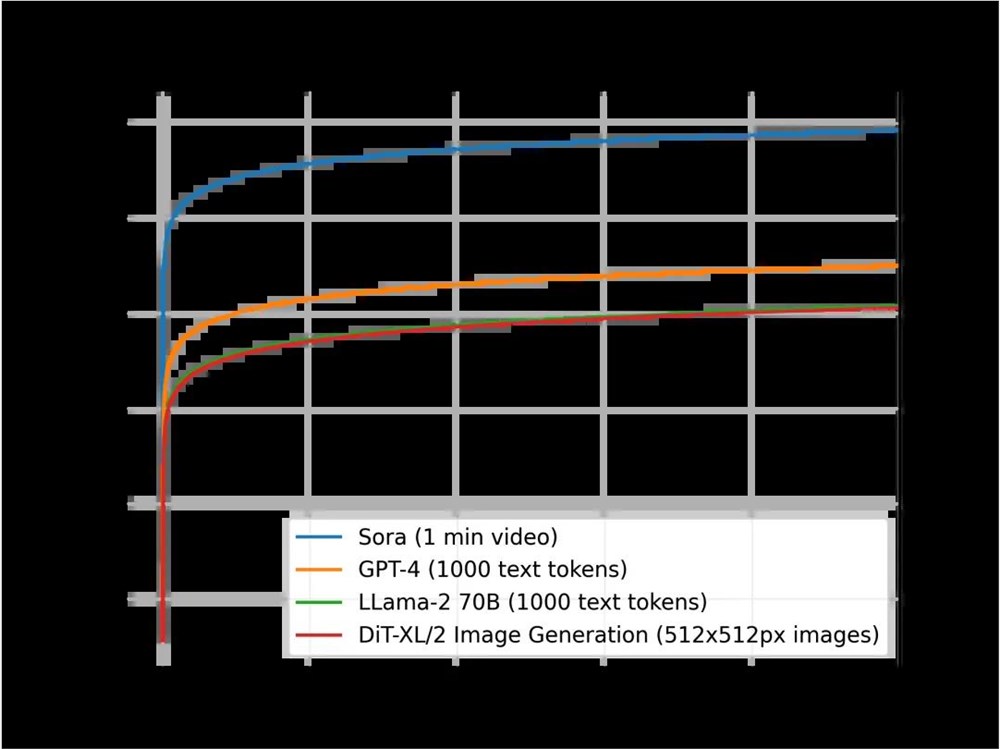
各模型每单位输出的推理计算量比较(Sora 为1分钟视频,GPT-4和 LLama 为21000个文本 token,DiT 为一张512x512px 的图片)。可以看到,本文估计 Sora 的推理计算成本要高出几个数量级。
本文比较了 Sora、D[]iT-XL、[]LLama2[]70B 和 GPT-4,[]并绘制了它们[]之间的对比图[](使用 FLOPS 的对数标度)[]。对于 Sora 和 DiT,本文[]使用了上文的[]推理估计值。[]对于 Llama2[]和 GPT-4,[]本文使用「F[]LOPS =2× 参数数量 × 生成的 token 数」这一经验[]公式估算 FLOPS 数。对于 GPT-4,[]本文假设该模[]型是一个专家[]混合(MoE[])模型,每个[]专家有220[]B 个参数,每个[]前向传递中有[]2个专家处于[]活动状态。不[]过对于 GPT-4,[]这些数字并未[]得到 OpenAI[] 的确认,因此[]仍需谨慎对待[]。
可以看到,像[] DiT 和 Sora 这样基于扩散[]的模型的推理[]成本要高得多[]:DiT-X[]L(一个拥有[]675M 参数的模型)[]与 LLama2[](一个拥有7[]0B 参数的模型)[]消耗的推理计[]算量大致相同[]。我们还可以[]看到,在推理[]工作负载方面[],Sora 甚至比 GPT-4更[]昂贵。
需要再次指出的是,上述许多数据都是估算值,依赖于简化的假设,没有考虑到 GPU 的实际 FLOPS 利用率、内存容量和内存带宽的限制以及推测解码等高级技术。
类 sora 模型获得显著的市场份额之后所需的推理计算量
本节根据 Sora 的计算需求推断出了需要多少台 Nvidia H100才能大规模运行类似 Sora 的模型,这意味着人工智能生成的视频已经在 TikTok 和 YouTube 等流行视频平台上实现显著的市场渗透。
假设每台 Nvidia H100每小时制作5分钟视频(详见上文),换言之每台 H100每天制作120分钟视频。
TikTok :假设人工智能的渗透率为50%,则每天的视频时长为1700万分钟(视频总数为3400万 × 平均时长为30s)
YouTube :每天4300万分钟视频,假设人工智能的渗透率为15%(大部分为2分钟以下的视频)
人工智能每天制作的视频总量:850万 +650万 =1070万分钟
支持 TikTok 和 YouTube 上的创作者社区所需的 Nvidia H100总量:1,070万 /120≈89000
再基于以下各种因素考虑,这一数字可能有些保守:
假设 FLOPS 的利用率为100%,并且没有考虑内存和通信瓶颈。实际上,50% 的利用率更符合实际情况,即增加1倍。
需求在时间上不是平均分布的,而是突发的。高峰需求尤其成问题,因为你需要更多的 GPU 才能满足所有流量的需求。本文认为,高峰需求会使所需 GPU 的最大数量再增加1倍。
创作者可能会生成多个候选视频,然后从这些候选视频中选出最佳视频。我们做了一个保守的假设,即平均每个上传的视频会生成2个候选视频,这又增加了1倍。
在峰值时,总共需要大约720000块 Nvidia H100GPU
这表明,随着生成式人工智能模型变得越来越流行且实用,推理计算将占主导地位。对于像 Sora 这样的基于扩散的模型,更是如此。
还需要注意的是,扩展模型将进一步大大增加推理计算的需求。另一方面,其中一些问题可以通过更优化的推理技术和跨堆栈的其他优化方法来解决。
视频内容的创意驱动了对 OpenAI 的 Sora 等模型最直接的需求。
原文链接:https://www.factorialfunds.com/blog/under-the-hood-how-openai-s-sora-model-works?continueFlag=8d0858264bc384419d2c0c1cfdc7d065










评论区
提示:本文章评论功能已关闭